
5 Amazing Papers Presented by Meta at ICML 2023

The prestigious International Conference on Machine Learning (ICML) is happening this year in Honolulu, Hawaii. At their 40th anniversary, experts in AI and ML from across the globe have gathered to showcase and release state-of-the-art research concerning all facets of machine learning deployed in closely interconnected domains such as AI, statistics, and data science. Furthermore, they have spotlighted vital application areas like machine vision, computational biology, speech recognition, and robotics. The firs took place in 1980 in Pittsburgh.
Let’s take a look at the papers that big tech Meta presented this year.
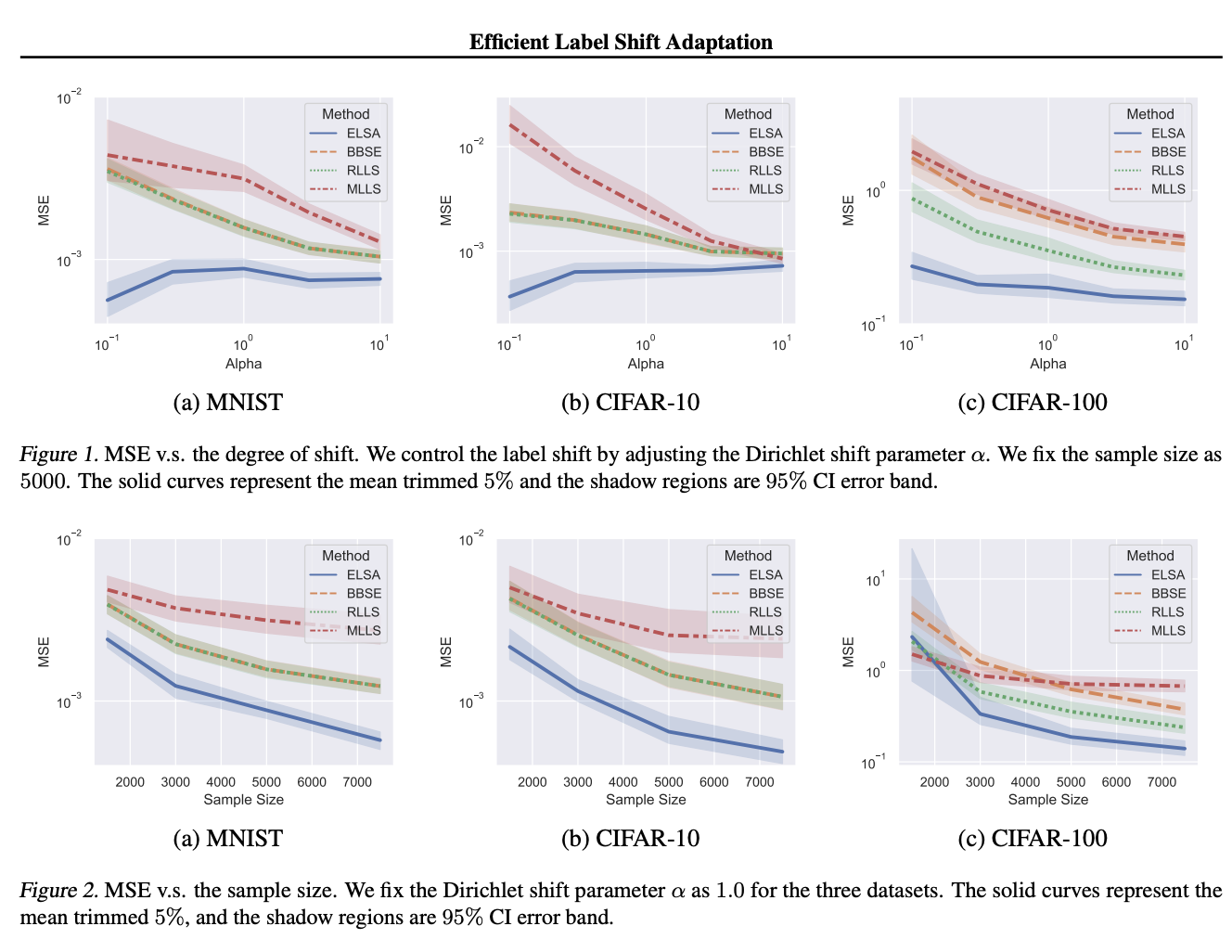
ELSA: Efficient Label Shift Adaptation through the Lens of Semiparametric Models
This study focuses on the problem of domain adaptation with label shift, where the distribution of labels differs between training and testing datasets while the distribution of features remains the same. Existing methods for label shift adaptation have estimation errors or complex post-prediction calibrations. To overcome these issues, the researchers propose a moment-matching framework called Efficient Label Shift Adaptation (ELSA). ELSA estimates adaptation weights by solving linear systems, ensuring accurate and efficient performance without post-prediction calibrations. Theoretical analysis proves its consistency and normality, while empirical results show state-of-the-art performance.
Reward-Mixing MDPs with a Few Latent Contexts are Learnable
This research focuses on episodic reinforcement learning in a type of decision-making process called “reward-mixing Markov decision processes” (RMMDPs). In these processes, at the start of each episode, nature randomly selects a hidden reward model from M choices, and the agent interacts with the system for H time steps. The goal is to learn a policy that maximizes cumulative rewards over H steps for this hidden reward model. The researchers present a new algorithm called EM2, which efficiently finds a nearly optimal policy for any M ≥ 2. They also establish a lower bound on the sample complexity of RMMDPs, showing that high sample complexity in M is unavoidable.
Read more: Meta-Qualcomm Partnership Will Bring Llama 2 to the Masses
Masked Trajectory Models for Prediction, Representation, and Control
Along with UC Berkeley, Georgia Tech and Google Research, Meta AI contributed to this project. Masked Trajectory Models (MTM) are a new way of making decisions step by step. The team takes a sequence of states and actions and try to figure out the sequence by using random parts of it. They learn to be flexible and can do different tasks just by using different parts of the sequence. For example, they can be used as models for predicting future actions, figuring out past actions, or even as a learning agent. In tests, the same MTM network can perform as well as or even better than specialized networks designed for specific tasks. MTM also helps speed up learning in traditional RL algorithms and competes well with specialized offline RL methods in benchmarks.
Hyperbolic Image-Text Representations
Meta introduced MERU which helps to organise visual and written ideas in a hierarchy. For example, when we say “dog,” it includes all dog images. Existing models like CLIP don’t explicitly capture this hierarchy. MERU uses hyperbolic spaces, which are good for representing tree-like data, allowing it to better capture the relationships between images and text. Results show that MERU creates a clear and understandable representation while performing as well as CLIP on tasks like image classification and image-text matching.

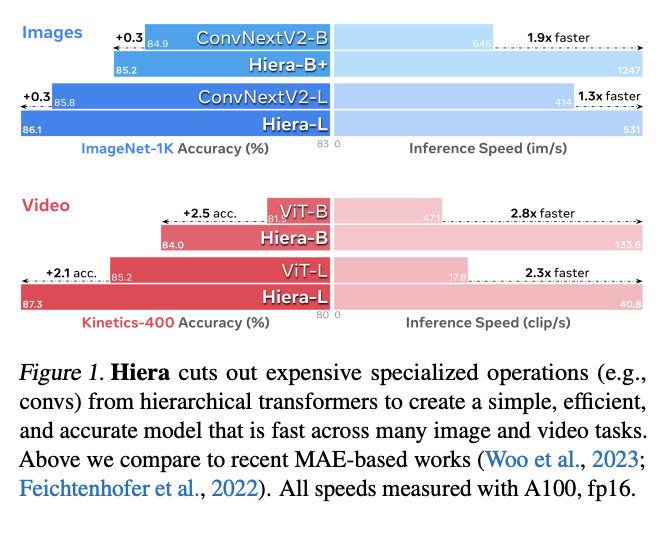
Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
Researchers have enhanced vision transformers for supervised classification, but the extra vision-specific elements have made them slower than the original ViT version. This paper introduces Hiera, a simple hierarchical vision transformer. By pretraining it with a strong visual task (MAE), unnecessary complexity is removed while maintaining accuracy. Hiera outperforms previous models, proving to be faster in both training and inference. Its performance is evaluated on various image and video recognition tasks.
Read more: Top 6 Papers Presented by Meta at CVPR 2023
The post 5 Amazing Papers Presented by Meta at ICML 2023 appeared first on Analytics India Magazine.


