
Google Introduces TransformerFAM, For Fixing Amnesia in LLMs
A team of researchers from Google has introduced Feedback Attention Memory (FAM), a novel Transformer architecture that leverages a feedback loop to enable the network to attend to its own latent representations, fostering the emergence of working memory within the Transformer and allowing it to process indefinitely long sequences.
Click here to check out the research paper.
“In the film ’Memento’ (2000), the protagonist struggles with anterograde amnesia, which means he can not remember anything that happened in the last 10 minutes, but his long-term memory is intact, He has to tattoo important information on his body to remember it. This is similar to the current state of large language models (LLMs),” reads the paper.
Similarly, current state-of-the-art large language models (LLMs) rely on attention mechanisms to extract meaningful representations from homogeneous data, but the quadratic complexity of attention with respect to context length limits the capability of modelling long contexts.
To address these limitations, researchers have explored techniques such as sliding window attention, sparse attention, and linear approximated attention, though these methods have shown effectiveness below the 1B scale.
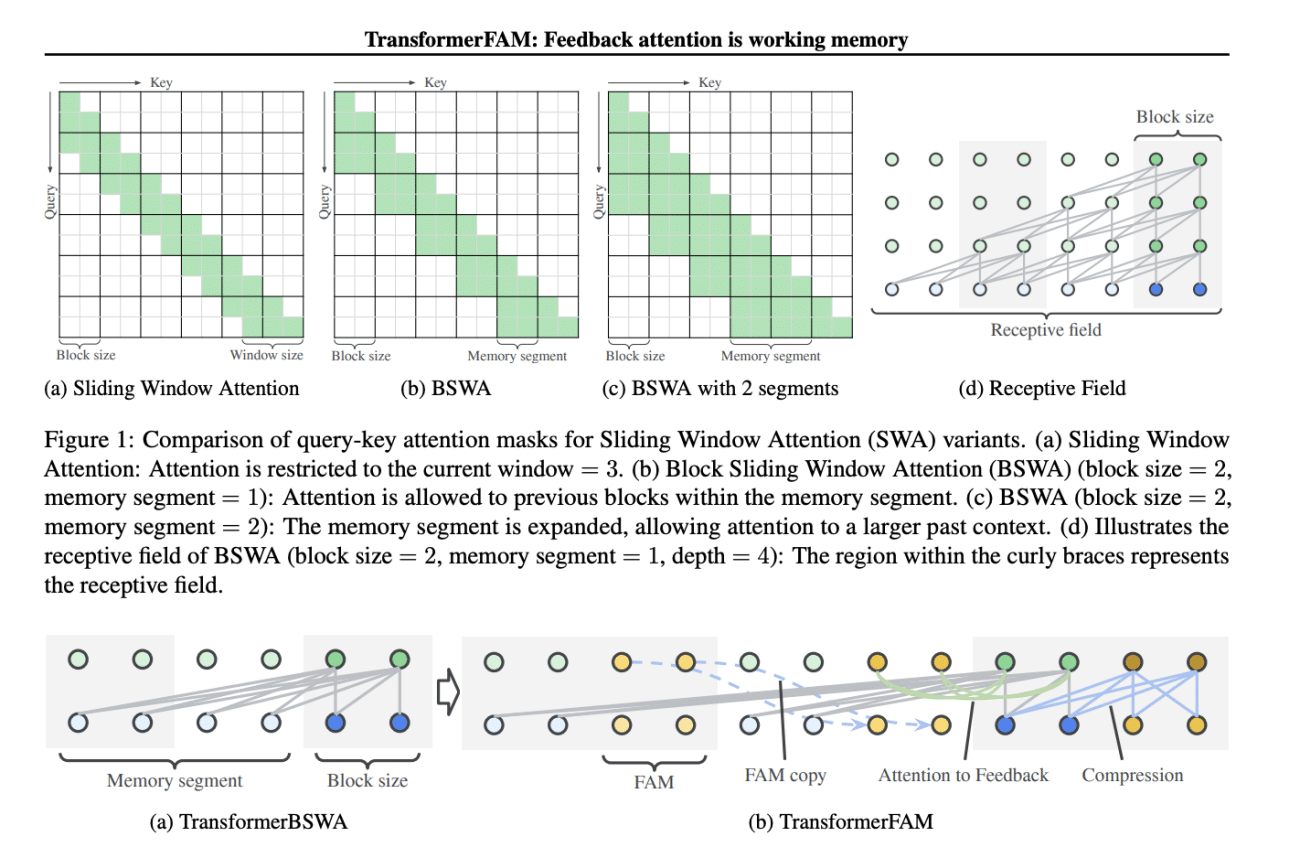
The introduction of Feedback Attention Memory offers a new approach by adding feedback activations that feed contextual representation back into each block of sliding window attention. This enables integrated attention, block-wise updates, information compression, and global contextual storage.
This innovative approach incorporates a feedback loop, which fosters the development of working memory within the Transformer architecture, allowing it to handle sequences of indefinite length. Notably, TransformerFAM can be seamlessly integrated with pre-trained models and does not require additional weights.
The architecture has been tested across various model sizes, including 1B, 8B, and 24B, and has demonstrated significant improvements in long-context tasks such as NarrativeQA, Scrolls-Qasper, Scrolls-Quality, and XLSum. By effectively compressing and retaining important contextual information within extremely long contexts, TransformerFAM has shown enhanced performance compared to other configurations.
The researchers emphasise the potential of TransformerFAM to empower LLMs to process sequences of unlimited length, which could revolutionise the way they handle long-context tasks and dependencies.
The paper highlights that although traditional Recurrent Neural Networks (RNNs) rely on causal relationships between input sequences, Transformers can efficiently exploit the parallelism of machine learning accelerators.
TransformerFAM’s feedback mechanism, which is limited to the relationship between blocks, does not compromise training efficiency and maintains performance levels similar to other architectures.
Recently, Google researchers also introduced a method for scaling Transformer-based large language models (LLMs) to handle infinitely long inputs with bounded memory and computation.
The post Google Introduces TransformerFAM, For Fixing Amnesia in LLMs appeared first on Analytics India Magazine.

