
AMD Loves Llama So Much

The open source community has a love affair with Llama, Meta’s open source large language model. So much so that, many of the models that are coming up in the generative AI ecosystem are based on top of Llama 2, and developers are using the model for all purposes. Why should AMD stay behind?
While demonstrating the kernel performance of the newly released AMD Instinct MI300X Accelerator at the Advancing AI event, Lisa Su, CEO of AMD, said that MI300X performs 1.2 times better than NVIDIA H100 on a single kernel when running Meta’s Llama 2 70B. “We are going to talk about this a lot,” Su said, speaking about Llama 2.
Su further goes on and demonstrates that when it comes to inference, one single server of AMD which consists of eight MI300X, performs 1.4 times faster than the server of an H100. Clearly, the performance of the MI300X is demonstrated the best with Llama 2.

Moreover, Kevin Scott, CTO of Microsoft discussed with Su on stage how AMD is contributing in Microsoft’s AI journey. While talking about the announcement at Ignite about using MI300X on Azure, Scott said that he is eager to Bring up GPT-4 and Llama 2 on MI300X and seeing the performance, and rolling it into production is something Scott said that he has been waiting for eagerly.
The mutual love for open source
“As important as the hardware is, software is what really drives innovation,” Su said, talking about the ROCm 6, the latest version of AMD’s open source parallel computing offering, which is an alternative to NVIDIA’s CUDA. ROCm 6 is releasing in the coming week.
Victor Peng, President of AMD, showed how building a strong ecosystem has enabled the company to create a successful open source framework in ROCm. For demonstrating this,
Peng showcased how MI300X with ROCm 6 is eight times faster than MI250X with ROCm 5, when inference Llama 2 70B.
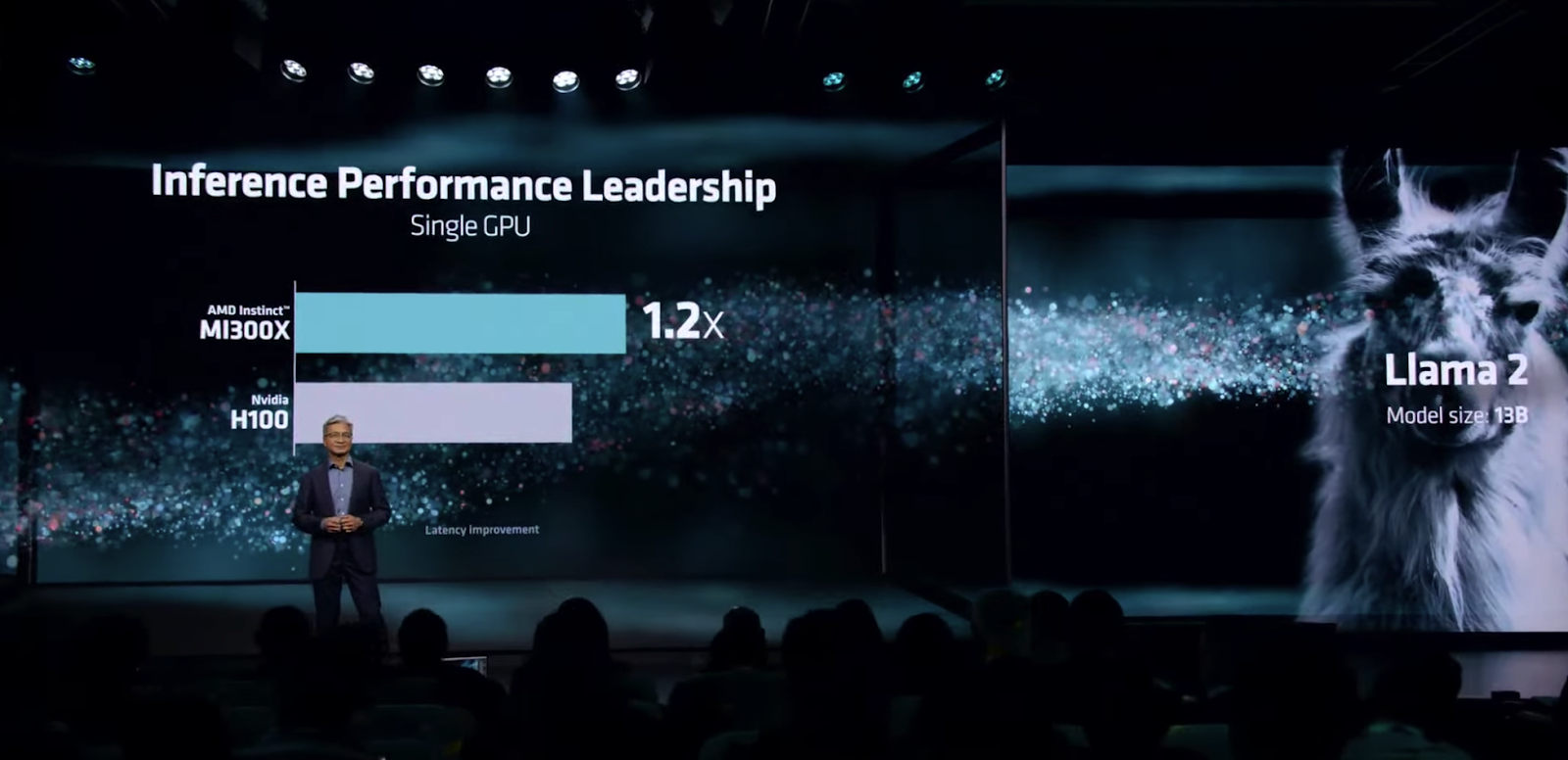
On smaller models such as Llama 2 13B, ROCm with MI300X showcased 1.2 times better performance than NVIDIA coupled with CUDA on a single GPU.
The most groundbreaking announcement is that Meta is partnering with AMD and the company would be using MI300X to build its data centres. To demonstrate this partnership, Ajit Matthews, Meta AI senior director engineering with Su said that MI300X is trained to be the fastest design-to-deployment solution in Meta’s history.
Meta has been using 150k H100 GPUs for research and training. It would be interesting to see how the shift to AMD MI300X takes place.
“We are investing for the future by building new experiences for people through our services, and advancing open technologies and research for the industry,” said Matthews. In July, Meta opened up Llama 2 family of models and, “we were blown away by the reception from the community,” he added.

“We believe that an open approach feeds to better and safer technology in the long run, as we have seen with the PyTorch and Open Compute project, and dozens of other AI models,” said Matthews, speaking about how AMD was also the co-founder of PyTorch with Meta.
“We completely agree with the vision and with the open ecosystem, and that being the path towards innovation with all the smart folks in the industry,” said Su also highlighting AMD’s focus on open software such as ROCm, along with the race towards open hardware with MI300X.
AMD’s long love for Meta
Meta has been working with AMD for EPYC CPUs since 2019. Meta also recently deployed AMD’s Genoa and Bergamo based servers at scale across its infrastructure. “We have been working with the Instinct GPUs, starting from the MI100, since 2020,” said Matthews. “We have also been benchmarking ROCm and working together for its support on PyTorch across each generation of AMD Instinct GPU.”
“As the Llama family of models continue to grow in size and power, which they will, the MI300X with its 192GB of memory and higher memory bandwidth meets the requirement for large language model inference,” added Matthews. He has also said he is pleased with the fact that AMD was specifically optimised ROCm for Llama models and Meta is seeing great performance numbers.
Not just bigger models, AMD is also focusing on edge computing with the introduction of Ryzen AI PCs, along with the first version of Ryzen AI software for building generative AI applications on your PCs by using pretrained models available on Hugging Face, such as Llama 2.

To demonstrate the performance of AMD Ryzen 8040, the newest version of its on-device neural processing unit (NPU), Su highlighted that Llama 2 7B performs 1.4 times faster than the previous versions. This marks the beginning of using small Llama 2 models on hardware powered by AMD.
The long running partnership with Meta, and the mutual love for open source is the reason why AMD loves Llama so much.
The post AMD Loves Llama So Much appeared first on Analytics India Magazine.

