
The Need for LLM Benchmarks in India

Any conversation about any LLMs is incomplete without how it fares on the various benchmarks like MMLU, HumanEval, AGIEval etc. Be it GPT-4 or Llama 2, the first criteria the creators try to showcase their LLMs is by putting up their benchmark scores on the research paper. Surprisingly, India, which is emerging as the new force in AI, does not have a benchmark of its own to evaluate LLMs.
In layman terms, we can say that LLMs are students and benchmarks are a kind of an examination for them on which they need to score good.
At present, discussions around generative AI predominantly revolve around China, the United States, and the Middle East, with notable players like TII (based in the UAE), Baidu (from China), and OpenAI (from the US) gaining significant attention.
There is still a need for a metric that India could utilise to evaluate LLMs, one that caters specifically to the country’s needs. Geography can also play a crucial role in understanding the purpose of an LLM, a factor that many people might not have paid attention to.
India is a diverse nation with a multitude of languages, cultures, and contexts. A benchmark specifically designed for India would take into account the linguistic diversity of the country. From addressing regional language nuances to recognizing cultural references, an Indian LLM benchmark could enable models to be more culturally sensitive.
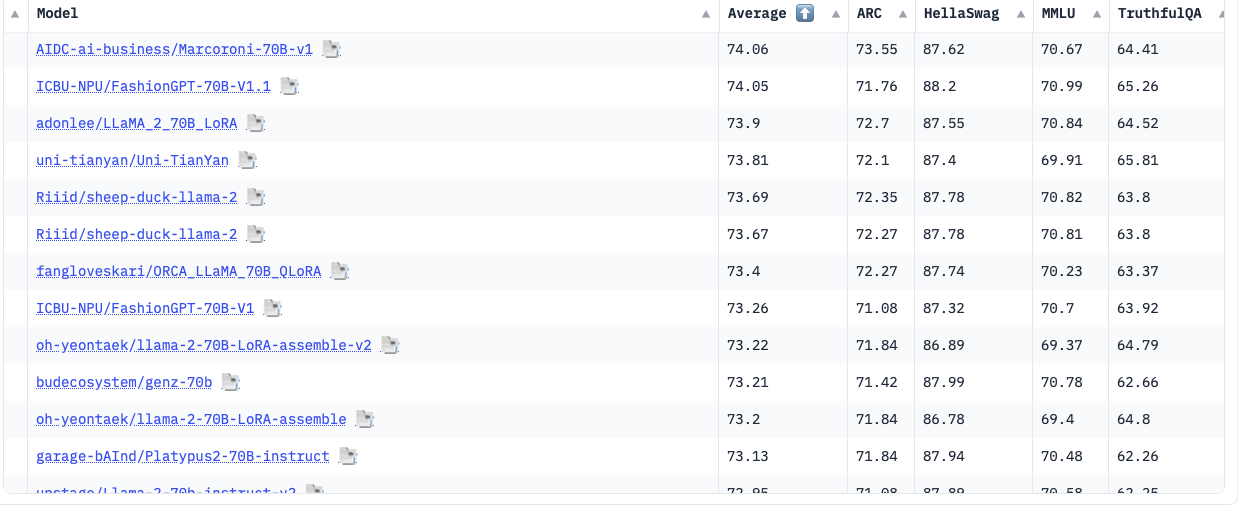
A glimpse of LLM Leaderboard with list of LLMs fairing across various benchmarks (Source: Hugging Face)
Developers from around the globe create models and submit them to Hugging Face, which maintains an LLM Leaderboard. Here, users can check which model is performing best on different metrics like MMLU, ARC, HellaSwag, and more. Hugging Face even calculates an average based on these metrics. Undoubtedly, it is a very useful tool. However, the question remains: are these metrics enough to judge an LLM? Perhaps to some extent, yes.
Indian Datasets
Majority of the benchmarks which have evolved from the U.S. take their exams into consideration. For example, MMLU, covers 57 tasks including elementary mathematics, US history, computer science, and law. Similarly AGIEval, is derived from exams like SAT, LSAT and other tests like Chinese College Entrance Exam (Gaokao), law school admission tests, math competitions, lawyer qualification tests, and national civil service exams.
In India, there are several tough competitive exams like UPSC, NEET, JEE-Advanced, CAT etc. which essentially covers the essence of India. Creating a benchmark for LLMs that’s tailored to Indian competitive exams like the UPSC would enable the development of language models capable of understanding the unique requirements of these exams, which often involve complex questions, diverse languages, and a deep understanding of India’s history, culture, and governance, alongside critical thinking and logical reasoning.
Earlier this year, AIM tried to check GPT-3 for UPSC, surprisingly it failed. However, a few months later GPT-4 was able to cross the cutoff.
Work in Progress
It is unfortunate that India hasn’t been able to create an LLM from scratch until now. However, the situation appears to be changing as NVIDIA recently partnered with Indian giants like Reliance, TATA, and Infosys.
Furthermore, the Indian IT giant Tech Mahindra is currently working on an indigenous LLM known as Project Indus. This model will have the ability to speak in many Indic languages, notably Hindi, and is planned to cover 40 different Indic languages initially. More languages originating from the country will also be added subsequently.
The way India might use these LLMs can be completely different from how the rest of the world. To understand Indian models at performing various tasks we need to create a benchmark based on regional or vernacular dataset.
Moreover models like GPT-4, Llama 2, Falcon 180B and Mistral 7B are mostly trained on datasets which are in English. There is a dire need of datasets created in Indian languages. As of today, the Indian constitution recognizes 22 major languages of India.
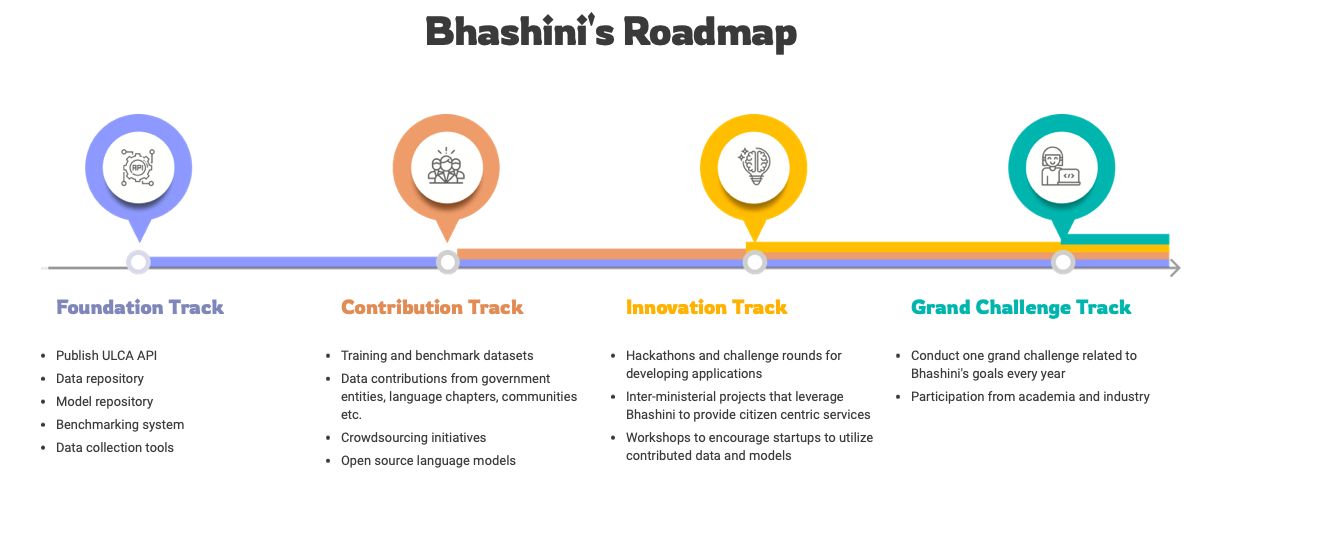
Thanks to the Indian government, it launched Project Bhashini Initiative where it looks at developing a National Public Digital Platform for local languages, which can be leveraged to create products and services for citizens using generative AI.
Similar to Hugging Face’s LLM Leaderboard that tracks, ranks, and evaluates open LLMs and chatbots, Bhashini intends to create training and benchmarking datasets. It will lead to healthy competition and will kickstart an LLM race in India.
What next?
Majority of the benchmarks are created by the research wing of universities or tech companies. For example, MMLU was created by the University of California, Berkeley. It’s high time that Indian universities like IIT Delhi, IIT Madras and IISc Bengaluru start working towards creating a dataset which will further lead towards the creation of a benchmark. Also, universities have easy access to data related to competitive exams.
However, creating a benchmark is easier said than done. It requires a lot of computational infrastructures in terms of GPUs to run those models against the dataset in order to get their efficacy in different metrics. To kick start the process Indian universities can partner with Indian tech companies like Reliance, Tata and Infosys who will soon acquire tens of thousands of NVIDIA GH200 Grace Hopper Superchip.
On his recent visit to India, NVIDIA chief Jensen Huang said that he will partner with universities like IITs as well to create AI infrastructure. “We would like to work with every single university. The first thing we have to do is build AI infrastructure” he said.
Isn’t it a nice thought seeing OpenAI’s models claiming supremacy over an Indian benchmark.
The post The Need for LLM Benchmarks in India appeared first on Analytics India Magazine.

