
Why AutoML sucks?

Today, a data scientist spends nearly 60-80 per cent of the time preparing the data for modelling. Once the model is developed, only a fraction of their time – i.e. 4 per cent – is gone into testing and tuning the algorithm. Further, the talent crunch in the AI/ML space is becoming challenging for many organisations.
To make the experience seamless, in 2018, Google released AutoML Vision, which built machine learning models automatically on image data, followed by AutoML for machine translation and natural language processing (NLP). AutoML was founded by Quoc Le, a pioneer in artificial intelligence. Le founded Google Brain in 2011, alongside Andrew Ng and Jeff Dean.

In little less than five years, AutoML has emerged as a go-to tool for many companies. According to Research&Markets, the AutoML market will touch $14.5 by 2030. The growth of the sector is said to be fueled by personalised product recommendation, the rising importance of predictive lead scoring, and others. Many industry experts also believe that the market is expected to increase in five years.
The bitter truth
Today, there are several players in the AutoML market, including tech giants, startups, and open-source solution providers. Some of them include Google Cloud AutoML, DataRobot, Darwin, and H20.ai.
But the question is, are companies really using AutoML? If yes, what are the use cases? If not, what is stopping businesses from using AutoML? – asked Mike Del Balso, cofounder and CEO at Tecton, on MLOps.community platform. Tecton is a Sequoia-backed enterprise feature store for machine learning.
“Most people do not use AutoML. I think that is because most AutoML systems suck for various reasons. I can list out a million possible reasons why, but I am actually not that confident that they are the correct reasons. AutoML should be awesome, but it is not. I am curious,” he added.
Clarifying the same, he said, “I kind of know why AutoML systems generally suck; they only do a tiny amount of the actual end-to-end job. For example, as a borderline cliche topic, when we talk about feature stores at Tecton, we often chastise AutoML tools for their deceptive demos. Just drag in *training_data.csv*, and then you have a model. Easy as that!. Sure, but where did training_data.csv come from!? The bigger question, though, is why do these tools suck?”
Laszlo Sragner, the founder at Hypergolic, said AutoML is much less of a holy grail than it is thought of. “When I see HP optimisation, the performance increase is marginal. The impactful activity is feature engineering, which is domain-specific and can not be automated,” he added, “If you get over this, AutoML is ‘just’ a job generator that queue’s up a set of experiments (might be dependent on each other so parallelisation can be tricky) based on some quantitative framework.”
Further, he said they might add too little value compared to what they do. If you can implement it with a bit of maths and glue code on your existing system, you won’t have the 10X benefit usually assumed to be needed to adapt to a new framework.
Sragner said that you need some (domain-specific language) DSL-like system to generate ‘experiments’, which is usually too restrictive to cover enough use cases.
Typically, an AutoML system needs to define the model and its features through an API/data definition. Or else, how will it know the space of possible candidates? – explained Sragner, revealing the codes –
{
'models': ['logreg', 'xgboost', 'nn', ..],
'layers': [0,1,2,3],
'features': ['name1', 'name2', ...
}
And so on.
“This is either too restrictive or too simple to be a killer feature. This potentially does not apply to systems that can deal with (abstract syntax trees) ASTs, namely, look at the code and change it arbitrarily (but I never heard about one), considering my negative opinion on the whole subject, it should be treated with not just a push, but a fist full of salt,” said Sragner.

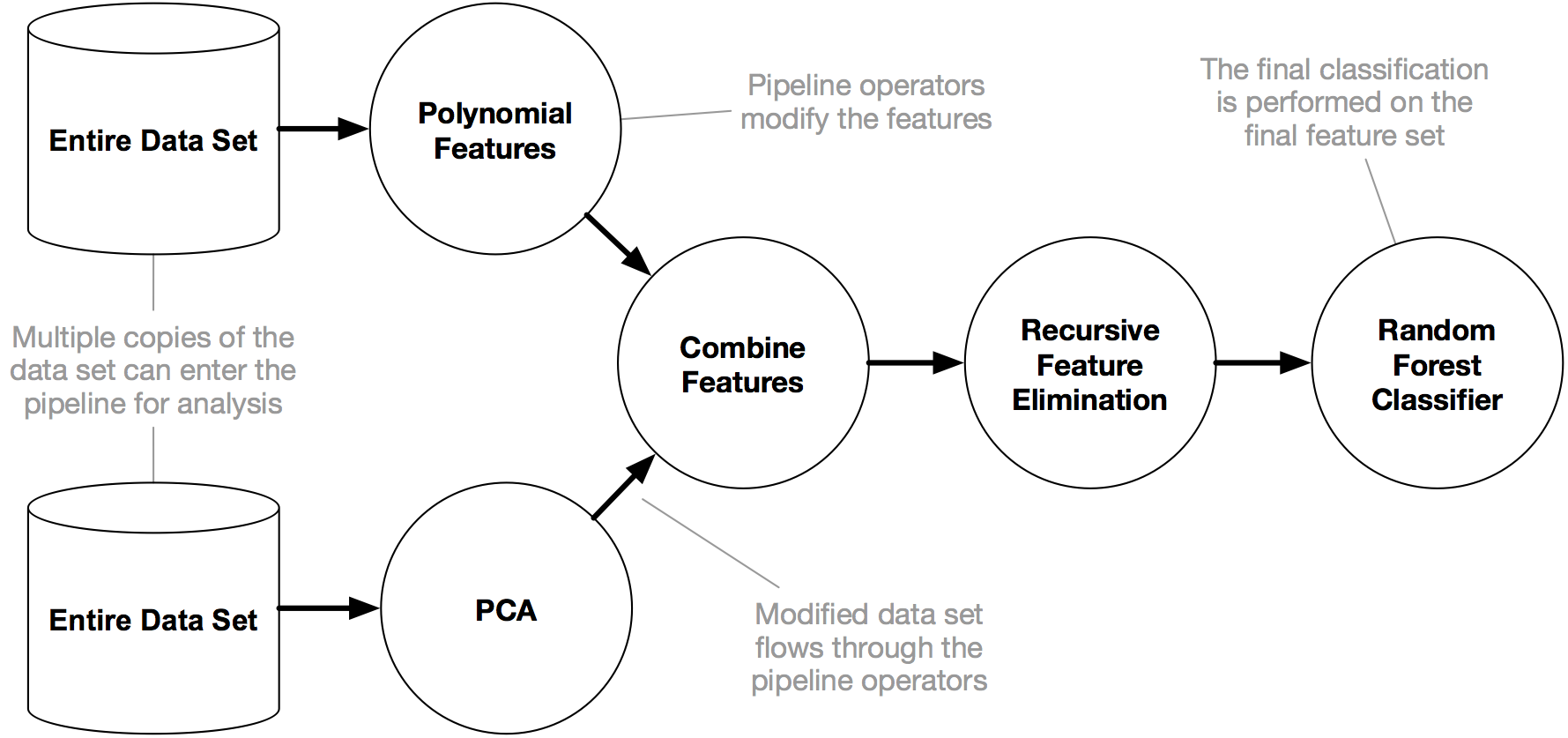
TPOT pipeline example (Source: GitHub). TPOT is an AutoML tool that optimises machine learning pipelines using genetic programming.
How awesome is AutoML?
Tomer Sagi, CEO and co-founder of EyeKnow AI, said that the complexity of an AutoML system should be judged by – what is automated? (scope), and how complex is the optimisation?
Further, he said that the current academic/open-source AutoML systems are restricted in the span of automation, i.e. they mostly attack the problem of algorithm/pipeline selection and HP tuning.
According to Sagi, AutoML can support:
- Auto data validation and testing
- Auto data reporting
- Auto feature generation and feature engineering
- Auto model profiling and reporting
- Auto model testing
- Auto model deployment (shadow deployment, canary release, etc.)
- Auto monitoring
- Auto retraining (if you have a way to generate labelled data)
Further, he said that the AutoML system could optimise other vectors besides pure performance (example: time and cost). For example, methods like hyperband can save significant training time and training cost, and the AutoML system can support multi-objective optimisation (example: optimising for both accuracy and query latency), shared Sagi.
“I do agree that at the end of the day, a competent engineer can ensemble a job queue and run experiments. However, the same argument can apply to most of the ML pipeline components (for example, a feature store). So, it all boils down to ‘build vs buy’ and ‘time to market,'” said Sagi.
Another AI expert, Nikolai, said AutoML has different forms of implementation. Some projects claim that hyperparameter optimisation is AutoML, but this is a narrow view. He said that AutoML is super awesome for him, where he can easily dump data and it:
- Builds bunch of viz based on data
- Performs target leakage detection
- Tries to extract features from data
- Tries all sorts of encoding, binning, dimensionality, reductions, clustering
- Tries most known models on data (interpretable vs flexible)
- Tries to do feature engineering (not domain-based)
- Feature reduction
- Tries to build blender and stack best models
- Builds model/compliance documentation
“You may ask what users actually do them? Frame problems, work with stakeholders to understand the business domain, build domain-based features, etc. For me, I enjoy coding, AutoML doing most of the repetitive leg work, now I can see what models tend to do better, the performance of engineered features and a bunch of already prepared information that I do not have to do manually. With this information, I can build an even better model,” said Nikolai.
“I am human. I may forget something or make a mistake; AutoML helps validate my assumptions and build in check to make sure I do not do stupid things (like leaking information from holdout),” he added.
AutoML in action
Data science architect Swaroop Gudipudi said that his company uses AutoML for recommendation systems that train periodically.
Tecton’s Balso said that AutoML has long promised to, well, automate ML, but somehow, that hasn’t really happened. “On the surface, it sounds super useful: people need to score leads, predict churn, and recommend products. Why not use an automated system to do that quite easily? Well, that is actually what people mostly do, but they do not call it AutoML; they just buy a product that automates their use cases for them,” he added. He said that he uses Stripe Radar to implement fraud detection on his models.
Further, he said, “AutoML tools typically underwhelm, but likely not always, and I don’t see why they have to underwhelm. I do not see any reason why we can not build a solid AutoML for production applications. Sure, it would be hard, but people do hard things. It would have to be super reliable, simple, and trustworthy. It would have to be truly end-to-end, and it would have to optimise our business outcomes, not AUC (area under the curve),” said Balso, ending on a positive note.
MLOps.community is an open community forum to discuss MLOps related problems and discuss best practices from engineers in the field. You can share your thoughts here.



{kind=link}