
Why Is Knowledge-Supervised Deep Learning Important
Researchers across the world are performing iterations and experiments to unlock the capacity that Artificial Intelligence (AI) has, in terms of recognition, solving complex problems, and providing accurate results. Unlike the recognition and observation developed by the human brain, machines largely have relied on inputs that are fed in a model, to fetch certain results. Researchers, however, aim to let neural networks function independently, with or without inputs— using graphs.
Right with Leonhard Euler’s invention of the graph theory in the 18th century, it has served to be one of the most efficient tools for analytics, to mathematicians, physicists, computer experts, and data scientists. Researchers and data scientists have extensively used “Knowledge graphs” to organise structured knowledge over the internet. The knowledge graph is a process to integrate information extracted from several sources and feed them to a neural network for processing.
Extrapolation is another way researchers think the AI can be trained to imagine the unseen, with structured inputs that are fed to any neural network. Unlike in machine learning, where humans train the parameters of any given model using data, the neural network in deep learning can self train itself using both— structured and unstructured data.
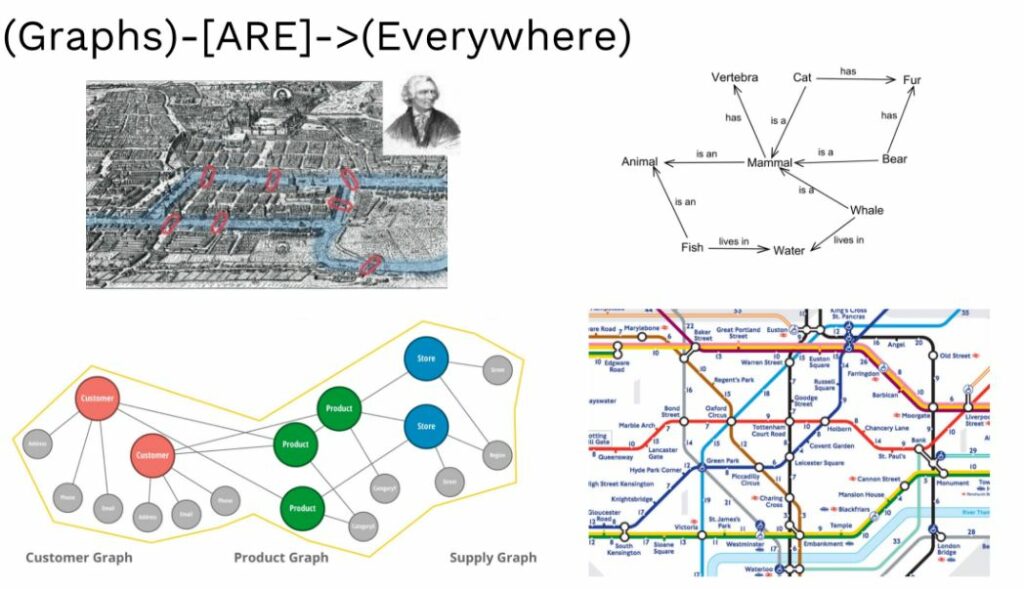
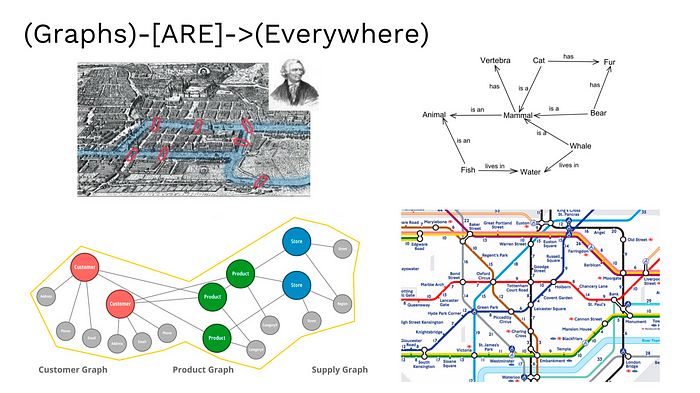
What is the purpose of a Knowledge graph?
Unlike any other technique, knowledge graphs have directed labeled graphs— with well-defined meanings for labels. These graphs have nodes, edges, and labels where anything can act as a node— for example an object, a place, person, or a company, etc. It is the “relationship of interest” between two nodes that are connected by edges. Labels define the meaning of relationships between nodes. For example, “employees” in a company are nodes and their respective “departmental managers” are the edges— the relationship here is defined with the label “colleagues”.
With the deployment of such nodes to edge networks in machine/ deep learning, data science researchers are working to make neural networks independent, in performing tasks. After having used PageRank which relied on links to rank a page on the web for authenticity, Google deployed knowledge graphs in its search mechanism, in 2012. According to Neo4j, when a search operation is performed on the web using the graph network, it is the latency of the query that is proportional to how much of the graph you want to traverse, rather than how much input is stored.
An open-source research organisation— Octavian, uses neural networks to perform tasks on “knowledge graphs”. While it is often said that deep-learning performs well with unstructured data, the superhuman neural networks modeled by Octavian deal with specific structured information and the neural architectures are engineered to suit the structure of the data they work well with.
One of Octavian’s data science engineers delivered a talk in 2018, at the Connected Data London conference, where he compared the traditional forms of deep learning to graph learning. The question he presented to establish his claim was “How would we like machine learning on graphs to look from 20,000 feet?”
As the neural networks require training to perform any task, his findings pointed out that many ML techniques in use on graphs have some fundamental limitations. While some techniques needed conversion of the graph into a table—discarding its structure, other techniques don’t work on unseen graphs. With an aim to overcome such limitations and use deep learning on graphs— the Octavian researcher identified certain “graph-data tasks” which demanded “graph-native implementations like Regression, Classification, and Embedding.
‘Relational Inductive Biases’
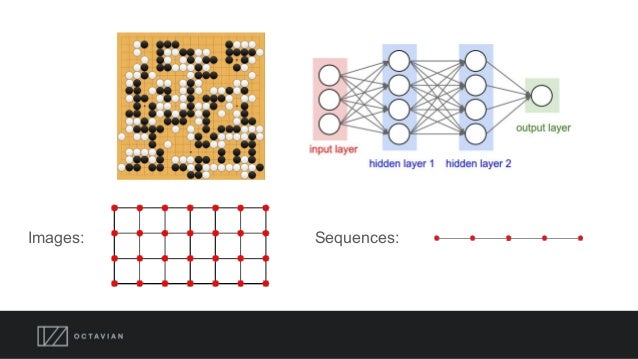
The focus in this study of using deep learning on graphs is on data structures that function well with neural networks. For instance, images are in a structured format as they are either two or three-dimensional— where pixels near to each other are relevant to each other than those which are far from each other. Whereas, sequences have a one-dimensional structure where items adjacent to each other are more relevant to one another than those that are far apart.
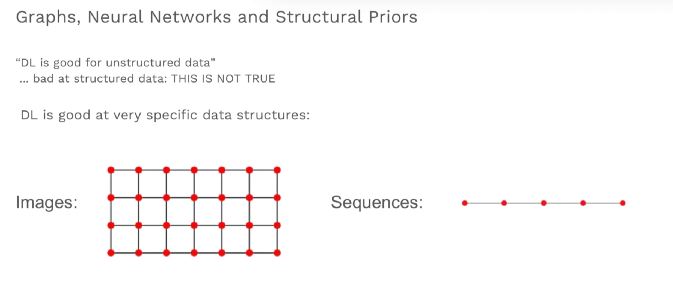
However, the nodes in graphs don’t have fixed relations like in images and sequences— the example of pixels and sequences. In order to achieve the best results in a deep learning model, Octavian claims that the creation of neural network models that match the graphs is the key. To establish the accuracy in results acquired by using deep learning of graphs, Google Brain along with MIT and the University of Edinburgh had released a paper on “Relational Inductive Biases”. The paper introduced a general algorithm to propagate datasets through a graph, and argued that a state of art performance can be achieved on the selection of graph tasks— by using neural networks to learn six functions to “perform aggregations and transforms within the structure of the graph”.
‘Combinatorial generalisation’
The combined thesis presented by Google Brain, MIT, and The University of Edinburgh argued that “combinatorial generalisation” is the top priority for artificial intelligence to achieve human-like abilities. The study argues that structured representations and computations are the keys to empower AI with analysing capabilities like that of a human brain. According to the paper, the graph network generalises and extends various approaches for neural networks that operate on graphs— to provide a straightforward interface for manipulation of structured knowledge and produce “structured behaviours”. The participants in this research have used deep learning on graphs to prove that neural network models yield more accurate results when they work with graphs.
Google’s knowledge graph
A well-established example of the aforementioned studies is Google. It has been using “knowledge graphs” for eight years. Rolled out on May 16, 2012, Google’s knowledge graph was invented to enhance the search experience. Using this graph, Google improvised its path to generate results for the search. In simple terms, when you search for the name of a movie ‘Batman: The Dark Knight’, the Google search yields all possible results with posters, videos, hoardings, advertisements, and the movie halls that are showing the film. It is the knowledge graph with deep learning that Google has been using to optimise its search engine, where billions of users arrive each day. It was Google’s X lab that built a neural network of 16,000 computer processors with 1 billion connections, after which the artificial brain browsed YouTube and searched for cat videos. No input was provided to the neural network, yet Google’s artificial brain used deep learning algorithms, combined with knowledge graphs— to perform one of the most common searches that even a human brain would.
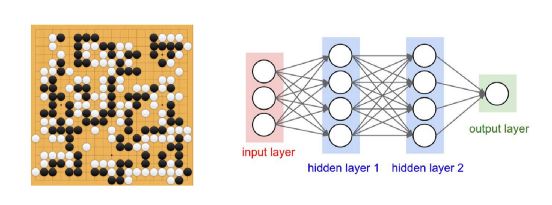
Graphs have proved to be the core of communication for the neural networks in deep learning. Such a learning process has several hidden layers which the network uses to generate the best results for any input. With knowledge graphs, Google has made groundbreaking achievements and acquired DeepMind in 2014 to further its research and study in deep learning algorithms. Google Assistant, Voice recognition on Facebook, and in your smartphones, Siri, Unlock using face recognition, fingerprint unlock and more are among several such innovations where AI has achieved recognition with analysis.
The post Why Is Knowledge-Supervised Deep Learning Important appeared first on Analytics India Magazine.

{kind=link}
{kind=link}
{kind=link}