
Researchers Expose Numerical Errors In NMT Systems
Researchers from the University of Melbourne, Facebook AI, and Twitter Cortex recently proposed a black-box test method for assessing and debugging the numerical translation of neural machine translation (NMT) systems. The new approach revealed novel errors common across multiple SOTA translation systems.
Mistranslation constitutes a critical but under-explored category with serious implications. For instance, in healthcare, mistranslating the number of confirmed cases of COVID-19 may exacerbate public health misinformation. Numerical errors made in financial document translation, for example, an extra or omitted digit or decimal point, could lead to significant monetary losses.
“Surprisingly, numerical mistranslation is a general issue faced by SOTA NMT systems, including commercial and research systems, with evidence present across contexts: for both high and low resource languages, and for both close and distant languages,” wrote the researchers, in ‘As Easy as 1, 2, 3: Behavioural Testing of NMT Systems for Numerical Translation’ paper, co-authored by Jun Wang, Chang Xu, Francisco Guzman, Ahmed El-Kishky, Benjamin I. P. Rubinstein, and Trevor Cohn.
The researchers believe their method extends the CheckList behavioural testing framework by designing automatic test cases to assess a suite of fundamental capabilities a system should exhibit in translating numbers. Their tests on SOTA NMT systems expose novel error types that have evaded close examination, as shown in the table.
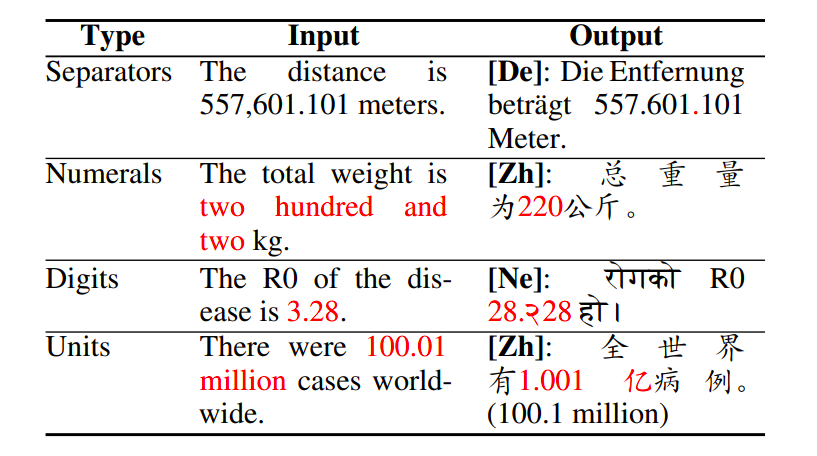
The researchers said these error types greatly extend the number category (NUM) of the catastrophic errors of NMT systems with richer error types. Finally, the abuse of these errors constitutes vectors of attack: error-prone numerical tokens injected into monolingual data may corrupt back-translation-based training, as the resulting back-translated sentences are likely to contain the desired errors.
Research
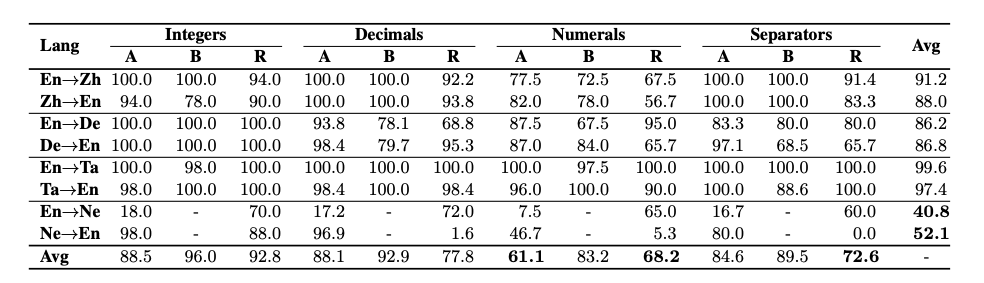
The researchers drew inspiration from the CheckList behavioural testing framework in designing their evaluation suite for NMT systems, alongside exploring four capabilities that demonstrate the expected translation abilities of systems on common numerical text: integers, decimals, numerals and separators.
The integers were tested on sequences of digits with ‘variable lengths’ and the decimals on ‘floating-point numbers’ with different levels of precision. The tested NMT systems were more likely to malfunction when translating larger integers and decimals with longer fractional parts. On the other hand, numerals were tested by numbers written in words and separators with numbers containing periods or commas.
“Systems that fail to manifest one or more of these capabilities may produce wrong numbers that can be inconspicuous to users and become a ready, exploitable source of misinformation,” revealed the researchers.

The team examined numerical formats of various lengths and decimal-point positions and tested them on 25 different formats across four capabilities. It allowed them to generate diverse numbers at scale, akin to fuzzing a programme with random inputs to uncover bugs. However, the researchers noted that all the numbers created for a format were seen as a set of ‘adversarial’ examples.
In addition to this, the researchers conducted their assessments in both high-resource and low-resource scenarios. High-resource set included English-German and English-Chinese pairs, and the low-resource set contained English-Tamil and English-Nepali pairs. The behaviour tests were run on popular commercial translation systems, with the team using pass rate (PR) as their evaluation metric.
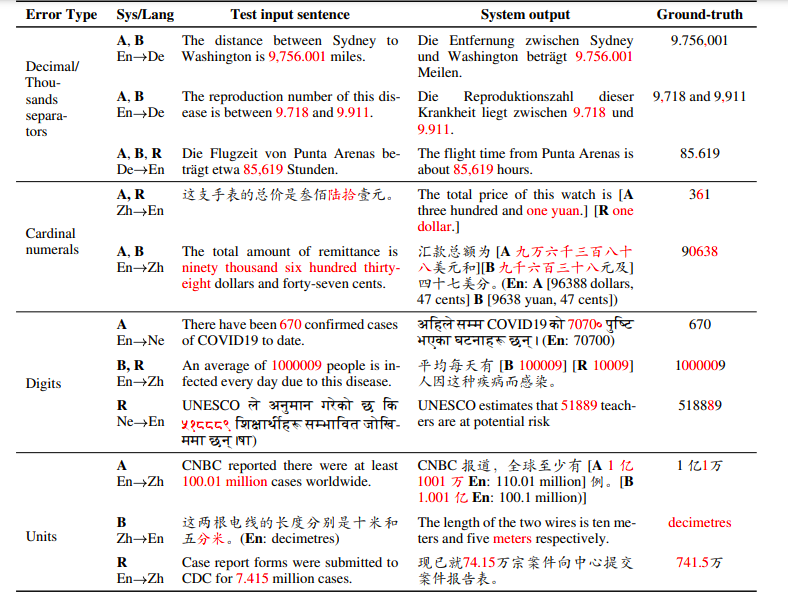
The researchers show examples of four major types of errors discovered by their tests/methods on three SOTA NMT systems. (Source: arXiv)
Conclusion
The researchers revealed numerical translation is a symmetric problem existing across all three tested SOTA NMT systems, with four major error types, including decimal/thousand separators, cardinal numerals, digits and units. The team has proposed several techniques to mitigate such errors, including data augmentation, the separate treatment of numbers, tailoring BPE segmentation and sanity checks.
“We hope that our study will help improve numerical translation quality and reduce misinformation caused by numerical mistranslation,” said the researchers.
The post Researchers Expose Numerical Errors In NMT Systems appeared first on Analytics India Magazine.

