
Guide to MESA: Boost Ensemble Imbalanced Learning with MEta-SAmpler
Class Imbalance is quite a known problem in datasets, and Imbalanced Learning is used to handle this problem by learning an unbiased model in the data. Existing approaches include Resampling, Reweighting, Ensemble Methods and Meta-Learning Methods. In this article, we will discuss one new method that has outperformed many of the previous methods. It combines both ensemble methods and meta-learning methods called MESA: Boost Ensemble Imbalanced Learning with MEta-SAmpler. This method was presented and submitted at Advances in Neural Information Processing Systems 33 pre-proceedings (NeurIPS 2020) by Zhining Liu, Pengfei Wei, Jing Jiang, Wei Cao, Jiang Bian, Yi Chang and this is a collaborative project of Jilin University, National University of Singapore, University of Technology Sydney and Microsoft Research.
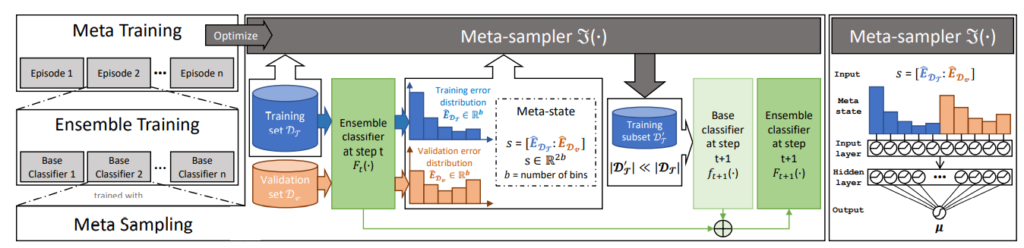
The key idea of the MESA framework is to create an automatic method of optimizing the imbalanced classification. It uses a meta-sampler for the ensemble training process. In each epoch of the training, the model takes the current classification error for both training and validation sets and on the basis of this, the meta-sampler selects a subset data to train a new classifier(for the balanced training dataset) and add it to the ensemble, to obtain the new state. Lastly, for meta-sampler to generalize the classifier in each iteration, Reinforcement Learning is used. Given below, is the workflow of MESA framework.
Requirements
- Python (>=3.5)
- PyTorch (=1.0.0)
- Gym (>=0.17.3)
- pandas (>=0.23.4)
- numpy (>=1.11)
- scikit-learn (>=0.20.1)
- imbalanced-learn (=0.5.0, optional)
Installation
!git clone https://github.com/ZhiningLiu1998/mesa.git
%cd mesaBasic Code Structure of using MESA
# load dataset
args = parser.ArgumentParser()
#making a dictionary of all the arguments so as to pass it to the model
config = parser.parse_known_args()[0]
print(config)
rater = Rater(config.metric)
X_train, y_train, X_valid, y_valid, X_test, y_test = load_dataset(config.dataset)
base_estimator = DecisionTreeClassifier()
# meta-training
mesa = Mesa(
args=config,
base_estimator=base_estimator,
n_estimators=10)
mesa.meta_fit(X_train, y_train, X_valid, y_valid, X_test, y_test)
# ensemble training
mesa.fit(X_train, y_train, X_valid, y_valid)
# evaluate
y_pred_test = mesa.predict_proba(X_test)[:, 1]
score = rater.score(y_test, y_pred_test)Demo of MESA via example
- Import all the required libraries and packages. The code snippet is available here.
- Make an argument parser and add all the required arguments for Soft Actor-critic and MESA.
- Load the dataset for classification, divide the dataset into train, validate & test, and plot the distribution of positive and negative classes. For example, we are using a Mammography dataset with majority class instances = 10,923 and minority class instances = 260, with the imbalance ratio of 42.012. The model which we are using is the Decision Tree Classifier. The code for it is shown below.
''' Prepare the Environment '''
# load dataset
dataset = 'Mammo'
X_train, y_train, X_valid, y_valid, X_test, y_test = load_dataset(dataset)
estimator, base_estimator = 'DT', DecisionTreeClassifier(max_depth=None)
n_estimators = config.max_estimators
# plot the class distribution
def plot_class_distribution(ax, labels, title):
sns.countplot(data=pd.DataFrame(labels, columns=['Class']), x='Class', ax=ax)
ax.set(title=title)
sns.set(style='whitegrid')
sns.set_context('talk', font_scale=1)
fig, ax = plt.subplots(figsize=(20, 6))
plot_class_distribution(
ax = ax,
labels = np.concatenate([y_train, y_valid, y_test]),
title = f'{dataset} dataset class distribution')
plt.tight_layout(pad=1.8)
plt.show()The distribution of classes is shown below:

- Initialize the MESA model.
mesa = Mesa( args=config, base_estimator=base_estimator, n_estimators=config.max_estimators)
Then start the training by using the meta_fit method.
# start meta-training
print ('Start meta-training of MESA ... ...')
start_time = time.clock()
mesa.meta_fit(X_train, y_train, X_valid, y_valid, X_test, y_test)
end_time = time.clock()
print ('Meta-training time: {:.3f} s'.format(end_time - start_time))
- Visualize the meta-training process. The code for it is available here.

- Compare the MESA method with other sampling techniques like SMOTE, BorderSMOTE, etc with 4 fold cross-validation and visualize the differences between the results. The list is shown below and the code snippet is available here.
resample_names = ['ORG', 'RUS', 'NM', 'NCR', 'ENN', 'Tomek', 'ALLKNN', 'OSS', 'ROS', 'SMOTE', 'ADASYN', 'BorderSMOTE', 'SMOTEENN', 'SMOTETomek']

Visualize the above result by plotting performance errors of all the imbalance learning methods. We can clearly see that this method outperforms the existing method with a huge margin.

Pros of MESA
- Compatibility: It is in terms of integrating the MESA model with the existing machine learning models.
- High data efficiency: MESA is a highly data-efficient method for the datasets with high skewness as, in each iteration, meta-sampler trains the data on the balanced subset.
- Good performance: Comparisons of MESA with other Imbalance Learning shows that MESA has outshined the existing methods
- Cross Talk Transferability: Meta-sampler can be used directly in unseen new tasks which save computational cost.
Cons of MESA
- Meta-training cost
- Meta-state is formed by distribution error of both training and testing datasets
- Unstable performance on small datasets.
Conclusion
In this article, we have discussed a novel imbalanced learning framework MESA. It is a generic method that can be integrated with various machine learning models. While there are many risks associated with Imbalance Learning especially when it comes to real-world problems but with proper usage and monitoring, it can be reduced and these types of techniques can make a difference in the decision-making process.
Official Code, Docs and Tutorials are available at:
The post Guide to MESA: Boost Ensemble Imbalanced Learning with MEta-SAmpler appeared first on Analytics India Magazine.


