
Scrape Beautifully With Beautiful Soup In Python
Web Scraping is the process of collecting data from the internet by using various tools and frameworks. Sometimes, It is used for online price change monitoring, price comparison, and seeing how well the competitors are doing by extracting data from their websites.
Web Scraping is as old as the internet is, In 1989 World wide web was launched and after four years World Wide Web Wanderer: The first web robot was created at MIT by Matthew Gray, the purpose of this crawler is to measure the size of the worldwide web.
Beautiful Soup is a Python library that is used for web scraping purposes to pull the data out of HTML and XML files. It creates a parse tree from page source code that can be used to extract data in a hierarchical and more readable manner.
It was first introduced by Leonard Richardson, who is still contributing to this project and this project is additionally supported by Tidelift (a paid subscription tool for open-source maintenance)
Beautiful soup3 was officially released in May 2006, Latest version released by Beautiful Soup is 4.9.2, and it supports Python 3 and Python 2.4 as well.
Advantage
- Very fast
- Extremely lenient
- Parses pages the same way a Browser does
- Prettify the Source Code
Installation
For installing Beautiful Soup we need Python made framework for the same, and also some other supported or additional frameworks can be installed by given PIP command below:
pip install beautifulsoup4.
Other frameworks we need in the future to work with different parser and frameworks:
pip install selenium
pip install requests
pip install lxml
pip install html5libQuickstart
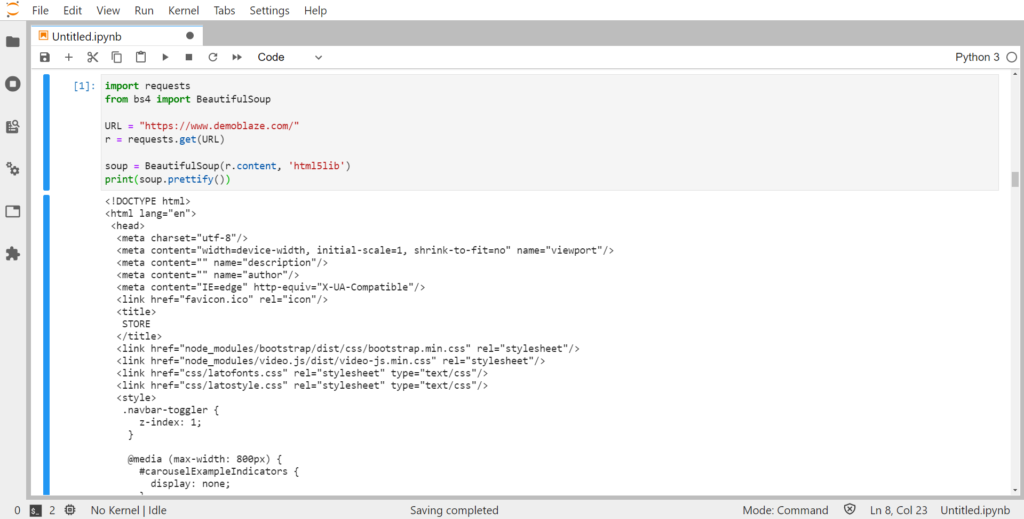
A small code to see how BeautifulSoup is faster than any other tools, we are extracting the source code from demoblaze
from bs4 import BeautifulSoupimport requests URL = "https://www.demoblaze.com/"r = requests.get(URL)
soup = BeautifulSoup(r.content, 'html5lib')
print(soup.prettify())Now “.prettify()” is a built-in function provided by the Beautiful Soup module, it gives the visual representation of the parsed URL Source code. i.e. it arranges all the tags in a parse-tree manner with better readability
prettify function
How to locate the data from the source code ?
For Excluding unwanted data and scrap reliable information only, we have to inspect the webpage.
We can open the Inspect tab by doing any of the following in your Web browser:
- Right Click on Webpage and Select Inspect
- Or in Chrome, Go to the upper right side of your chrome browser screen and Click on the Menu bar -> More tools -> Developer tools.
- Ctrl + Shift + i
Now after opening the inspect tab, you can search the element you wish to extract from the webpage.

By just hovering through the webpage, we can select the elements; and corresponding code will be available like shown in the above image.
The title for all the articles is inside Class=”post-article”, and inside that, we have our article title in-between “span” tags.
With this method, we can look into web pages’ backend and explore all the data with just hover and watch functionality provided by Chrome browser Inspect tools.
Let’s Extract Some data !
In this example, we are going to use Selenium for browser automation & source code extraction purposes.
A full tutorial about selenium is available here.
Our purpose is to scrape all the Titles of articles from the Analytics India Magazine homepage.
#importing modules
from selenium import webdriver
from bs4 import BeautifulSoup
options = webdriver.ChromeOptions()
options.add_argument('--ignore-certificate-errors')
options.add_argument('--incognito')
options.add_argument('--headless')
driver = webdriver.Chrome(chrome_options=options)
source =driver.get('https://analyticsindiamag.com/')
source_code=driver.page_source
soup = BeautifulSoup(source_code,'lxml')
article_block =soup.find_all('div',class_='post-title')
for titles in article_block:
title =titles.find('span').get_text()
print(title)

Let’s break down the above code line by line to understand how it can detect those article titles:
- First, two lines were to import BeautifulSoup and Selenium.
from selenium import webdriver
from bs4 import BeautifulSoup
- Then we started the chrome Browser in Incognito, and headless mode means no chrome popup and surfing web URLs; instead, it will boot up the URL in the background.
options = webdriver.ChromeOptions()
options.add_argument('--ignore-certificate-errors')
options.add_argument('--incognito')
options.add_argument('--headless')
- Then with the help of Selenium driver, we loaded the given URL source code into “source_code” variable.
source_code=driver.page_sourceNote: We can extract given URL source code in many ways, but as we already know about selenium, So it’s easy to move forward with the same tool, and it has other functionalities too like scrolling through the hyperlinks and clicking elements.
- Passing “source_code” variable into ‘BeautifulSoup’ with specifying the ”lxml” parser we are going to use for data processing,
- Now we are using the Beautiful soup function “Find” to find the ‘div’ tag having class ‘post-title’ as discussed above because article titles are inside this div container.
soup = BeautifulSoup(source_code,'lxml')
article_block =soup.find_all('div',class_='post-title')
- Now with a simple for loop, we are going to iterate through each article element and again with the help of “Find” we extract all the “span” tags containing title text.
- “get_text()” is used to trim the pre/post span tags we are getting with each iteration of finding titles.
for titles in article_block:
title =titles.find('span').get_text()
print(title)
After this, you can feed the data for data science work you can use this data to create a world, or maybe you can do text-analysis.
Conclusion
Beautiful Soup is a great tool for extracting very specific information from large unstructured raw Data, and also it is very fast and handy to use.
Its documentation is also very helpful if you want to continue your research.
You learned how to:
- Install and setup the scraping environment
- Inspect the website to get elements name
- Parse the source code in Beautiful Soup to get trimmed results
- Live example of getting all the published article names from a website.
The post Scrape Beautifully With Beautiful Soup In Python appeared first on Analytics India Magazine.
