
Now AI Can Generate Images From Captions
While massive language models like GPT-3 have impressed the public with its extraordinary capabilities in composing articles, short shorties, songs and poems, many have severely scrutinised the technology as a mere parlour trick. However, researchers at Allen Institute for Artificial Intelligence (AI2) believe that the underlying technology that has been used to develop GPT-3 can have immense potential to advance AI as a whole.
GPT-3 is a text-based model, which has been trained on an enormous amount of internet data, but researchers at AI2 utilised the same methods to train both texts as well as images. To take this idea forward, the researchers developed a visual language model — X-LXMERT, which can generate images, if provided with a caption.
The model can run both on texts as well as images; however, the outcome images aren’t as realistic as generated by GANs. But, according to the researchers, this development can show a promising new direction for making smarter robots with generalisable intelligence.
Also Read: Can This Tiny Language Model Defeat Gigantic GPT3?
How Does It Work?
X-LXMERT — the computer vision explorer model, is an extension of LXMERT, which is a cross-modality transformer model pre-trained on several vision and language datasets. The model, after pre-training, has further been fine-tuned for various downstream tasks.
With that being said, the researchers noted that the visual features regressed by LXMERT are not suitable for image generation. Therefore, similar to the VideoBERT model, the researchers first created a visual vocabulary using K-mean clustering and then modified the LXMERT model to predict the cluster-ID for each masked visual token.
The experiment will show that by discretising visual representations results, researchers will be able to predict better visual features and generate rich imagery. So following the BERT model, this proposed model also leverages Bernoulli sampling to identify the position of the masked tokens on visual and textual features. However, to generate images from the caption, all the tokens on the visual side must be masked as well as predicted.
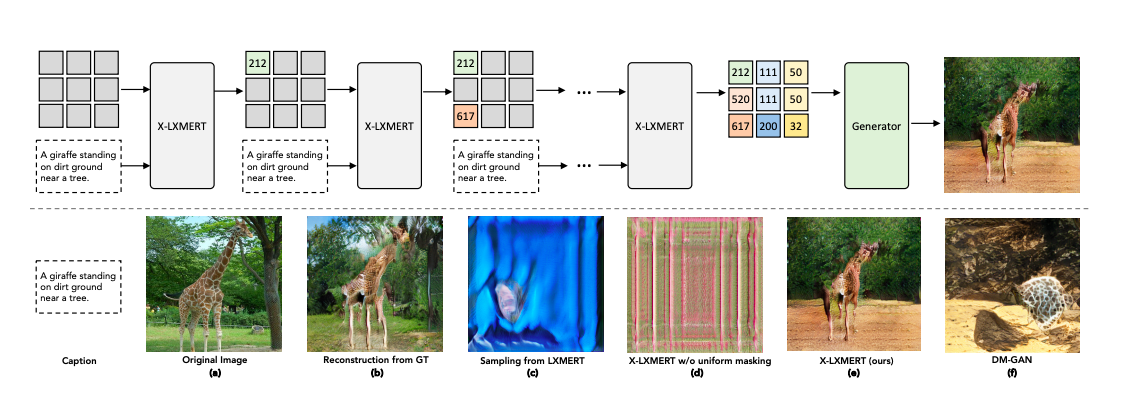
Generation architecture that can reconstruct images using ground truth pre-trained grid features.
But, researchers noted that low probability Bernoulli sampling procedure does not allow the model to perform well at generation tasks. Further, it also increases the probability of very high values which leads to poor pre-training of the model. Thus, to resolve this, researchers used uniform masking on the visual modality.
With X-LEMERT’s uniform masking, researchers first sampled the masking ratio from a uniform prior distribution and then they can sample the desired number of positions randomly. This advancement subjects the model to a variety of masking ratios, and with the proposed experiment, researchers showcased how it can significantly benefit image generation.
To facilitate this, firstly, the researchers had to update the pre-training data. The LXMERT model uses a variety of data, starting from QA data to caption data from COCO and Visual Genome, but considering the proposed model — X-LXMERT uses the CCC loss function, these data are unsuited to train the CCC objective. Therefore, X-LXMERT drops QA data and the captions from VG for CCC objective for visual cluster prediction and deployed Gibbs sampling to iteratively sample features at different spatial locations.
Post that; the researchers deployed autoregressive sampling and non-autoregressive sampling for sampling locations on the square grid. With this, it has been noted that non-autoregressive sampling with Mask-predict-K has produced good results across a variety of generation metrics. And, when used in X-LXMERT, the uniforms masking aligns well with the linear decay of Mask-Predict, which makes the model robust to a number of masked locations.

Images generated by X-LXMERT from the captions below them.
While experimenting, researchers presented experimental setups to evaluate the model on image generation, visual question answering and visual reasoning. To which, it was noted that X-LXMERT significantly outperforms LXMERT across all generation metrics of image generation. Further, it also surpassed the performance of two specialised generation models — comparable to AttnGAN and ControlGAN.

While the transformer employed in X-LXMERT is large, its image generator is much smaller than the one used by DM-GAN. Although it doesn’t provide realistic images, the image quality of X-LXMERT image generator is expected to improve when coupled with DM-GAN.
Also Read: The Tech Behind Mayflower Autonomous Ship
Conclusion
While developing the probing mechanism, researchers observed that LXMERT is not able to generate meaningful images given on text. And that’s why they presented X-LXMERT, a unified model for image generation, which showcases that proposed extensions can easily be applied to other vision-and-language transformer models.
Further, the team plans to carry out more experiments in order to improve the quality of the image generation and scale the model’s visual and linguistic vocabulary to include more topics, objects, and adjectives.
Read the whole paper here.
The post Now AI Can Generate Images From Captions appeared first on Analytics India Magazine.
